
目前我是清华大学的博1学生😁. 此前我曾在🐜担任研究型实习生. 我的本硕均在南京理工大学, 是 PCALab 的一员. 此外, 我曾受到国家公派资助(CSC, IGSF), 作为 University of Dayton 的本科交换生, 进行为期一个学期的访学, 并取得了 4.0/4.0 的成绩, 入选当年 Deans’ List. 目前我已经有 6 篇一作/共一的学术论文被国际会议接收 (4A2B), 因为多次的实习变动导致”略懂”的研究方向非常多(CV->NLP).
我是一个横向发展,纵向研究的人。我在多个略有相关的领域展开了广泛的研究,并发表了一些还不错的论文。 我的研究方向包括但不限于:
- 数字人动作生成 (Motion Generation): ICASSP24,AAAI25 👑Oral
- 三维渲染 (3D Rendering): ICASSP24 👑Oral
- 脑机接口交叉研究 (AI4Neuro): ICML25
- Agentic RAG & RL (LLM): AAAI26.
如果您觉得我的研究方向很难理解,下面这个 VCR 可以很好的概述我的研究历程,即先重建我的人体,后根据一段音乐,生成我的舞蹈动作,最终,我和一个机器人一起跳舞,实现群舞的效果:
如果您对我的研究方向感兴趣(或者对我感兴趣)并有意向合作, 也随时欢迎联系我😆! 我非常喜欢合作, 会成为你非常好的合作伙伴!
👨👩👧👦 Internship
- 2025.03 - 2025.08, 🐜蚂蚁集团, 杭州, 研究型实习生 (Research Intern) 💡产出: AAAI *1 ICLR 在投*1
- 2024.09 - 2025.03, 上海 AI Lab 浦江实验室, 上海, 实习生 (Intern) 💡产出: ICML*1
- 2024.06 - 2024.09, 光明实验室, 深圳, 论文合作者, 💡产出: TPAMI*1
- 2024.05 - 2024.09, 南京大学苏州校区, 江苏苏州, 科研助理 (RA), 💡产出: AAAI2025 oral*1
- 2023.4 - 2024.03, 清华大学深圳国际研究生院(THU), 深圳, 科研助理 (RA), 💡产出:ICASSP2024 oral*1, ICASSP2024 poster*1
🔥 News
- 2025.12: 🎉 公开1篇共一 arxiv 论文
- 2025.11: 🎉 一作论文 WebFilter, TCDiff++ 分别被 AAAI26, IJCV25 接收! 参与工作 LogicBench/LogicCLIP 被 AAAI 2026 接收为 👑Oral!
- 2025.10: 🎉 公开1篇新的 arxiv 论文!
- 2025.09: 🎉 公开2篇新的 arxiv 论文!
- 2025.08: 🎉 RealFactBench 被 ACMMM Datasets Track 接收, CARD 被 EMNLP 接收, 公开3篇新的 arxiv 论文!
- 2025.07: 🎉 数字人综述被 TPAMI 接收, MERD-14 被 ACM MM 接收为 👑Oral!
- 2025.06: 🎉 FloorPlan-Lamma ACL 2025 接收为 👑Oral, ⭐SAC Highlight, 公开3篇新的 arxiv 论文!
- 2025.05: 🎉 MindAligner 被 ICML 2025 接收!
- 2024.12: 🎉 TCDiff 被 AAAI2025 接收为 👑Oral!
📝 Publications
一作/共一论文(8)

[AAAI25 Oral]Harmonious Group Choreography with Trajectory-Controllable Diffusion


Yuqin Dai, Wanlu Zhu, Ronghui Li, Zeping Ren, Xiangzheng Zhou, Xiu Li, Jun Li, Jian Yang.
- 发现并提出领域内存在的问题: 舞者混淆(Dancer Ambiguity)现象. 为后续研究提供指引与思路.
- TCDiff 是当前 SOTA 的多人舞蹈生成模型, 能够较好的解决舞者混淆(Dancer Ambiguity)现象.
- 提出了 Footwork Adaptor 模块, 能有效缓解多人舞蹈生成中的脚步滑动问题(Foot Slide).
- 提出了 Fusion Projection 插件, 该插件占用较小的计算资源, 能够有效解决舞者混淆(Dancer Ambiguity)现象
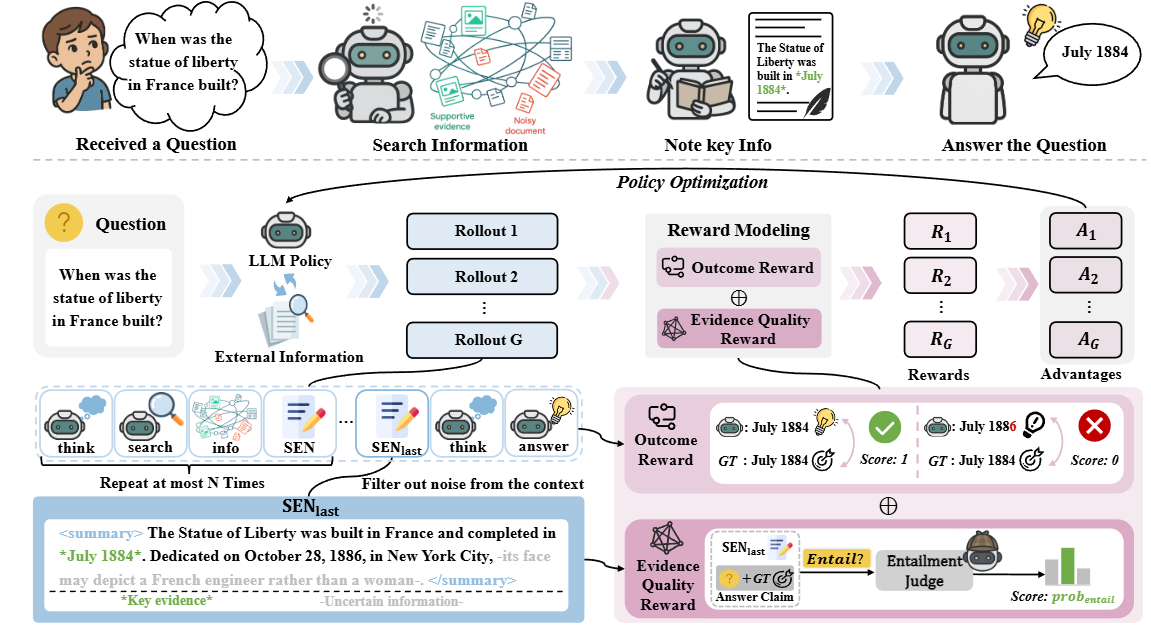
[arXiv25]EviNote-RAG: Enhancing RAG Models via Answer-Supportive Evidence Notes


Yuqin Dai*, Guoqing Wang*, Yuan Wang*, Kairan Dou, Kaichen Zhou, Zhanwei Zhang, Shuo Yang, Fei Tang, Jun Yin, Pengyu Zeng, Zhenzhe Ying, Can Yi, Changhua Meng, Yuchen Zhou, Yongliang Shen, Shuai Lu
- 我们提出 EviNote-RAG 框架,将“检索-回答”模式改为“检索-笔记-回答”,提升信息提炼和推理可靠性。
- 引入类人类的检索式摘要机制,生成支持性证据笔记(SENs),突出关键信息和不确定点,减少噪音、提升聚焦。
- 方法在多个问答基准上达到 SOTA,不仅效果显著提升,还大幅增强训练稳定性和效率,例如在 HotpotQA、Bamboogle、2Wiki 上分别提升 F1 20% (+0.093)、40% (+0.151)、91% (+0.256)。
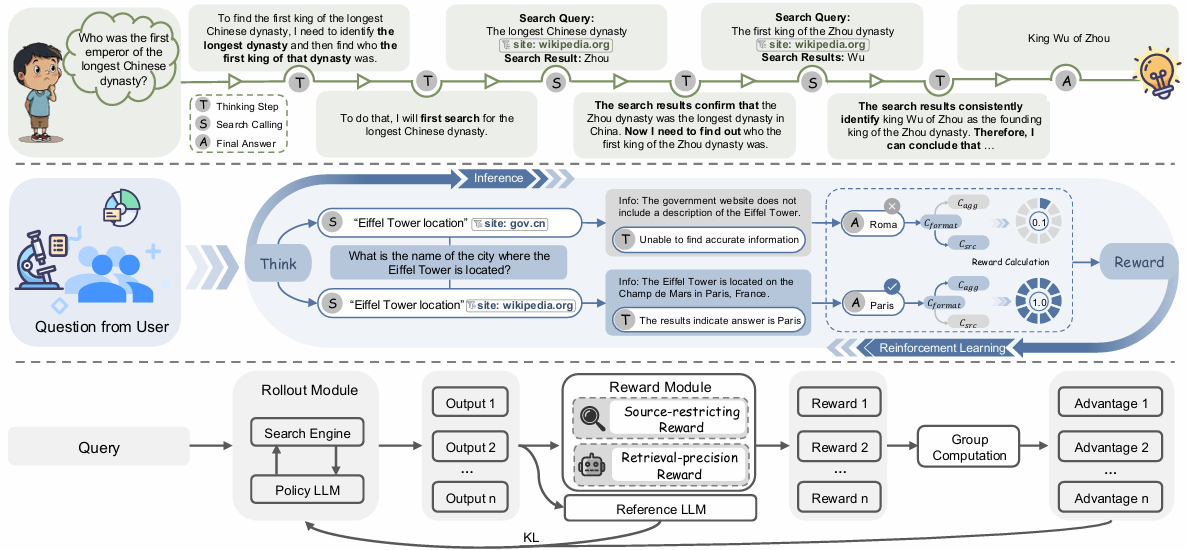


Yuqin Dai*, Shuo Yang*, Guoqing Wang*, Yong Deng, Zhanwei Zhang, Jun Yin, Pengyu Zeng, Zhenzhe Ying, Changhua Meng, Can Yi, Yuchen Zhou, Weiqiang Wang, Shuai Lu
- 我们提出了 WebFilter 框架,将检索过程建模为马尔可夫决策过程,并通过强化学习训练大语言模型使用高级网页搜索操作符,从而在真实网络环境中有效过滤虚假信息。
- 设计了信息过滤奖励策略,结合“来源限制奖励”和“检索精度奖励”,同时优化查询行为与检索结果质量,显著提高了检索精准度与可信度。
- 实验表明,WebFilter 在多项问答基准上取得了最优性能,高级搜索操作符的使用率由 10% 提升至 75%,并在域内与跨域任务中均展现出强泛化能力。
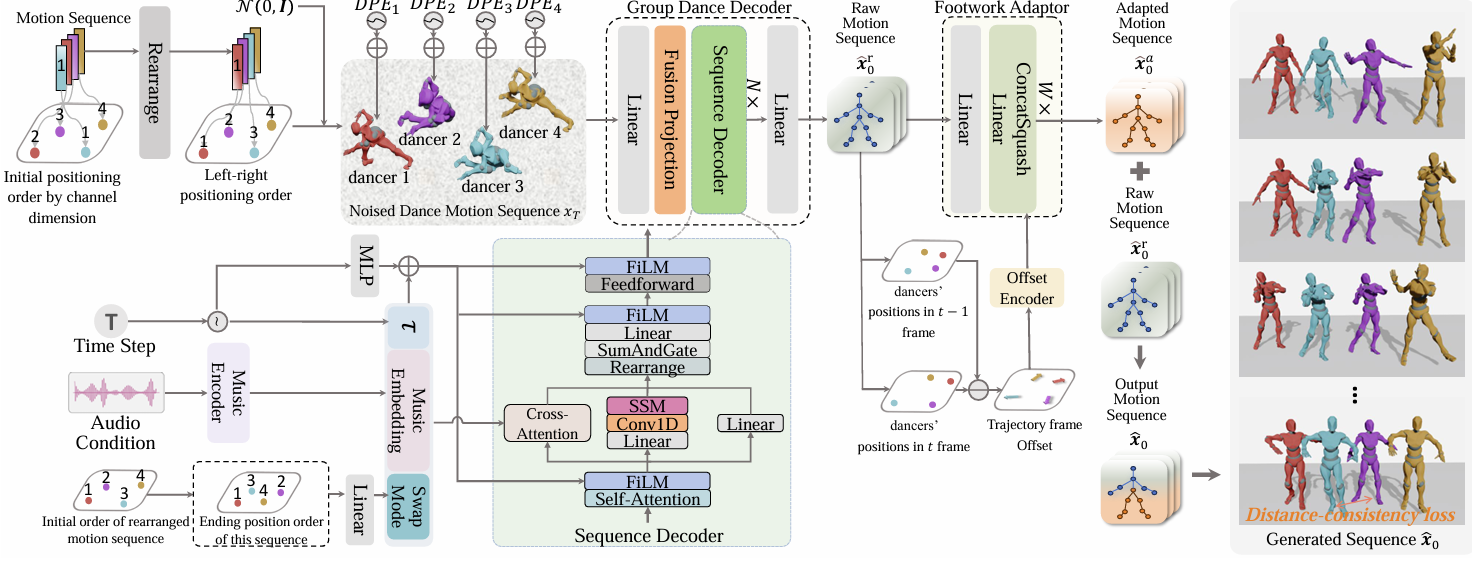


Yuqin Dai*, Wanlu Zhu*, Ronghui Li, Xiu Li, Zhenyu Zhang, Jun Li,Jian Yang
- 我们提出TCDiff++, 一种端到端版本的群舞生成模型。
- 我们引入位置嵌入和一致性损失,防止碰撞并保持合理间距。
- 模型加入换位信息和脚步自适应器,减少脚滑并提升一致性。
- 优化长时生成效果,提出长序列采样与解码器,优化长舞蹈生成的连贯性。
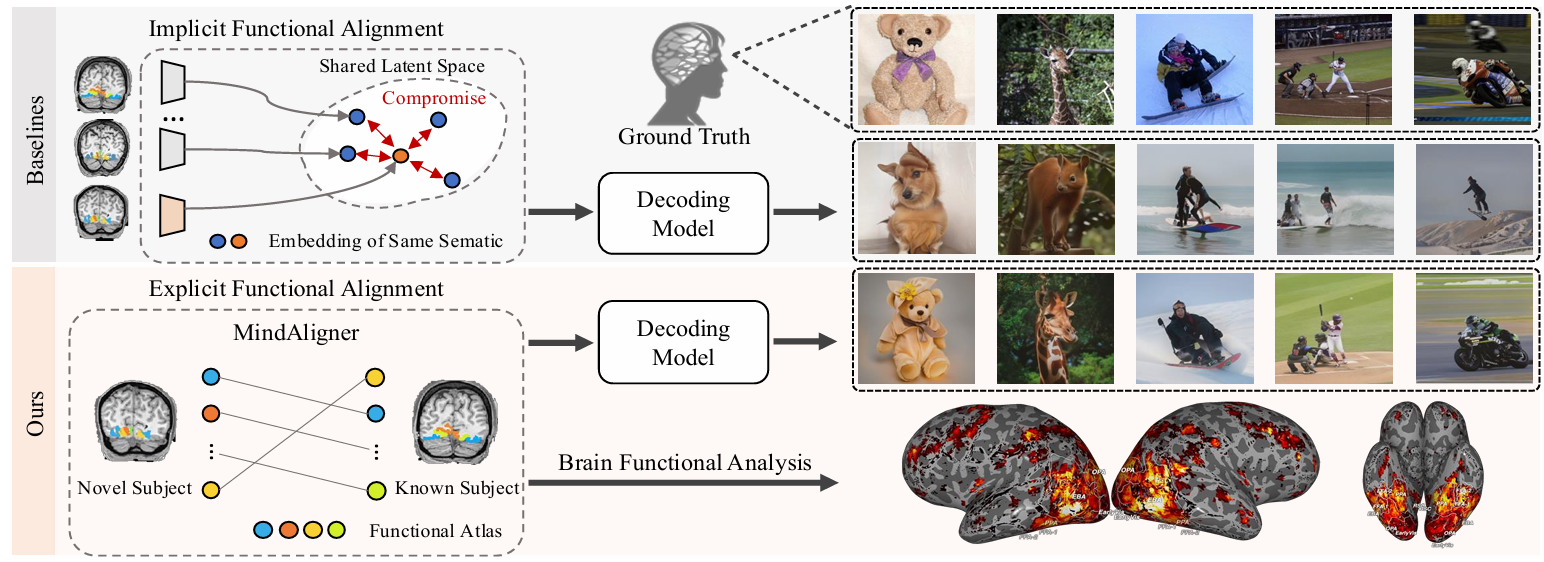


Yuqin Dai*, Zhouheng Yao*, Chunfeng Song, Qihao Zheng, Weijian Mai, Kunyu Peng, Shuai Lu, Wanli Ouyang, Jian Yang, Jiamin Wu.
- 我们提出了MindAligner,这是第一个显式的大脑对齐框架,能够在数据有限的情况下实现跨个体的视觉解码和大脑功能分析。
- 我们提出了一种大脑转移矩阵,用于建立不同个体之间的细粒度功能对应关系。该矩阵通过大脑功能对齐模块进行优化,采用多层次对齐损失实现软性跨个体映射。
- 实验表明,MindAligner在视觉解码任务中,只有6%的模型参数被学习时,便超越了现有的最先进方法。
- 我们进行了跨个体的大脑功能可视化研究,发现早期视觉皮层在不同个体间活动相似,而与记忆和空间导航相关的高级视觉皮层则表现出显著的个体间差异。
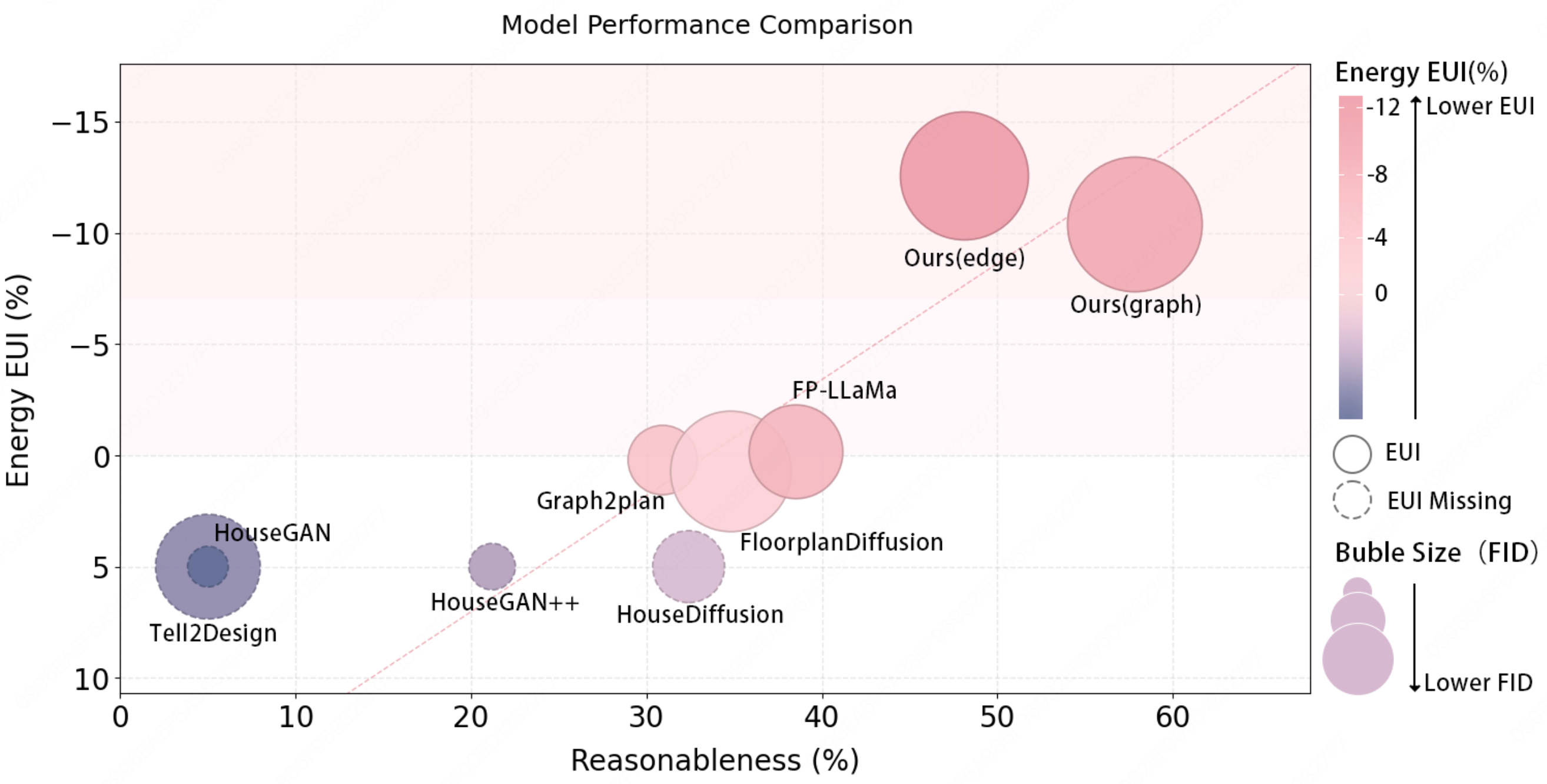
Pengyu Zeng*, Yuqin Dai*, Jun Yin*, Jing Zhong, Ziyang Han, Chaoyang Shi, ZhanXiang Jin, Maowei Jiang, Yuxing Han, Shuai Lu†
- 提出了 GreenPlanner 框架:将“设计评估”与“生成”统一起来的节能住宅设计框架。它解决了现有生成方法缺乏自动评估机制、容易产生不符合现实约束(如能耗过高或空间功能缺陷)的布局的问题,实现了兼顾可持续性和空间功能合理性的自动化设计。
- 构建了两个关键数据集:DesignFD(设计可行性数据集):包含带有专家验证的能耗和空间功能标签,用于学习设计约束的先验知识。GreenPD(绿色平面图数据集):基于 DesignFD 并通过评估器筛选和修正得到的,它将用户需求与符合法规的布局配对,消除了无效样本(从 60% 降至 0%),为训练提供了高质量数据。
- 开发了核心模型 PDE 与 GreenFlow:PDE(实用设计评估器):能够快速预测能耗表现和空间功能有效性,准确率超过 99%。GreenFlow 生成器:一种基于流(flow-based)的生成模型,利用 PDE 的反馈进行训练,实现了在现实约束下的可控布局生成,相比专业建筑师的设计效率提升了 87%。
[ICASSP24 Oral]Text2Avatar: Text to 3D Human Avatar Generation with Codebook-Driven Body Controllable Attribute
Chaoqun Gong*, Yuqin Dai*, Ronghui Li, Achun Bao, Jun Li, Jian Yang, Yachao Zhang, Xiu L.
- Text2Avatar 是第一个基于复杂耦合的输入文本提示生成逼真风格的 3D Avatar 的模型,实现了多属性可控和逼真的 3D 人头像生成。
- Text2Avatar 模型基于 3D-Aware GAN(NeRF-Based), 使用 GAN-Inversion based 的方式实现文本对齐, 巧妙化解了当前文本标注的写实风格三维 Avatar 数据集缺失的问题.
- 提出 Multi-Modal Encoder, 能够作为插件服务于其他模型, 具有很强的可扩展性.
[ICASSP24]EXPLORING MULTI-MODAL CONTROL IN MUSIC-DRIVEN DANCE GENERATION
Ronghui Li*, Yuqin Dai*, Yachao Zhang, Jun Li, Jian Yang, Jie Guo, Xiu Li.
- 提出了第一个统一的框架,能够生成高质量的舞蹈动作,并支持多模态控制,包括同时进行流派控制、语义控制和空间控制。
- 模型能够进行音乐跨模态舞蹈生成(Music2Dance), 基于 VQ-GPT 架构, 能够一次生成长达 16s 的舞蹈动作, 并能通过自回归的方式对生成内容进行拓展.
参与工作(9)
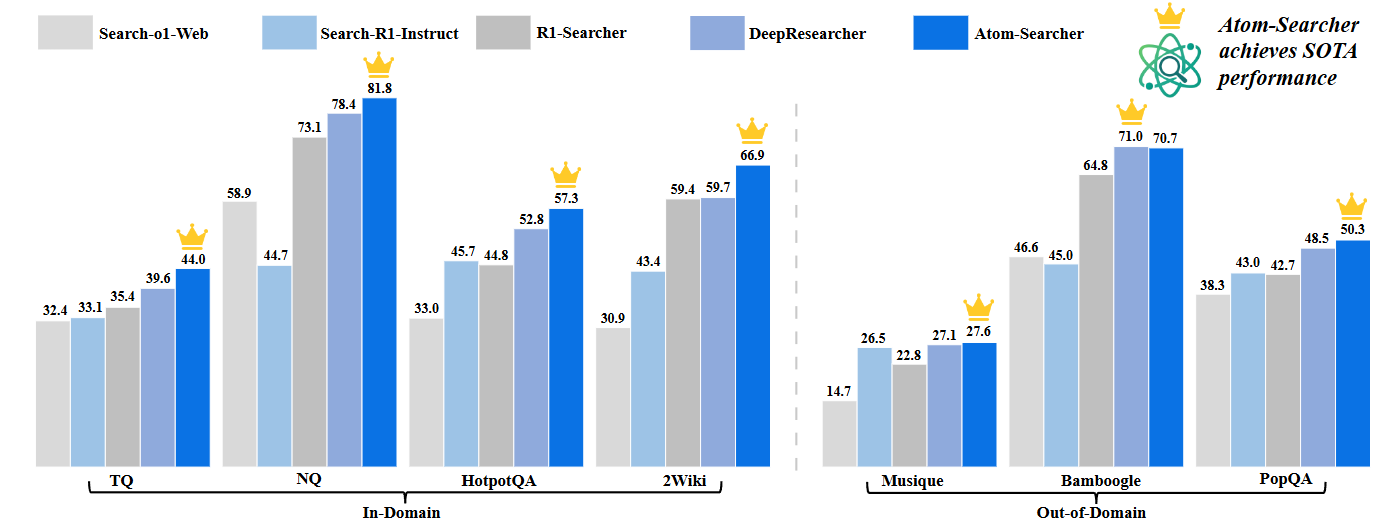
[arXiv25]Atom-Searcher: Enhancing Agentic Deep Research via Fine-Grained Atomic Thought Reward


Yong Deng∗, Guoqing Wang∗, Zhenzhe Ying∗, Xiaofeng Wu∗, Jinzhen Lin, Wenwen Xiong, Yuqin Dai, Shuo Yang, Zhanwei Zhang, Qiwen Wang, Yang Qin, Changhua Meng
- 提出全新的“原子思维”范式:将大模型的推理过程拆解为细粒度的功能单元,从而引导模型进行更清晰、更深入的推理。
- 设计原子思维奖励机制(ATR)及课程式聚合策略:通过将 ATR 与最终结果奖励结合,缓解了策略优化中的梯度冲突和奖励稀疏问题。
- 构建 Atom-Searcher 框架并验证效果:基于原子思维与奖励聚合策略,提出了一个新的强化学习框架 Atom-Searcher,在七个基准测试上超越现有最优方法,并展现出多方面优势。
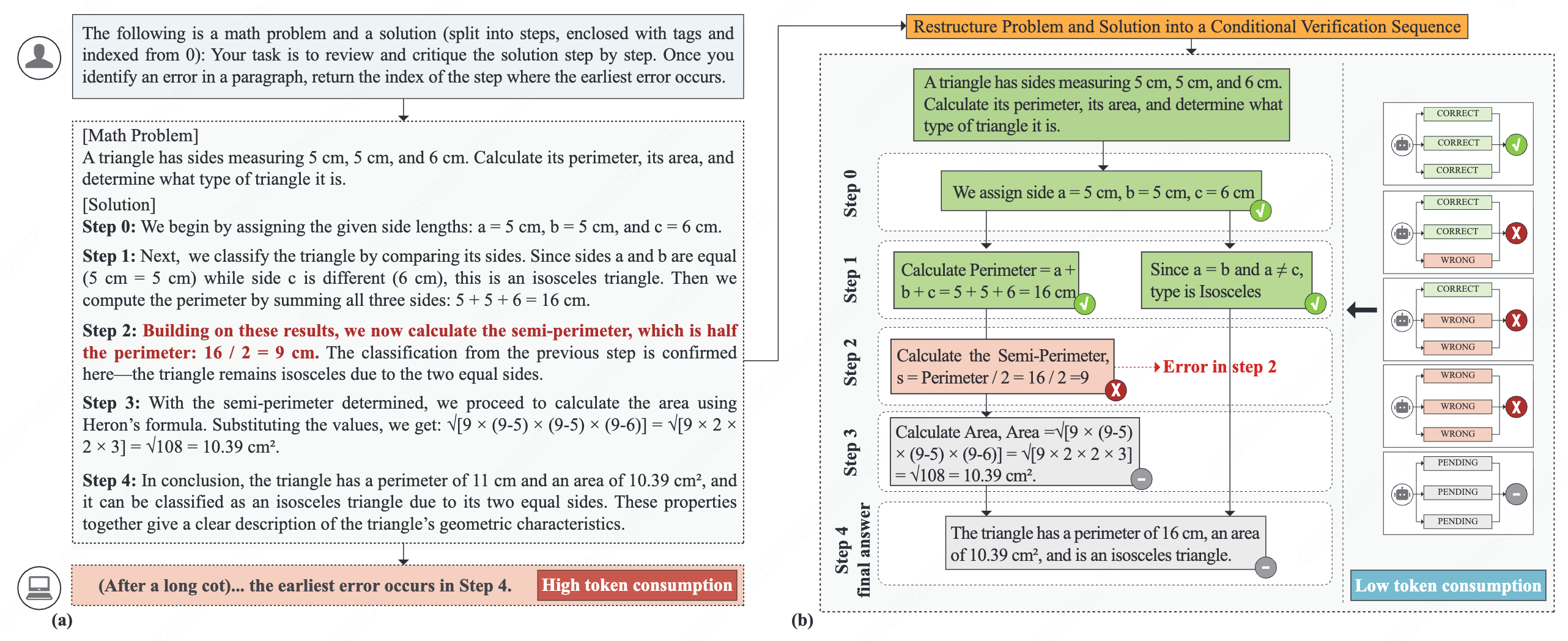
Zhang, Yulong; Wang, Li; Du, Wei; Li, Peilin; Yuqin Dai; Zhao, Zhiyuan; Fang, Lingyong; Liu, Ziniu; Zhang, Ru; Zhu, Huijia; Liu, Gongshen
- 提出了一种名为 NCV 的免训练框架,通过将复杂的思维链推理重构为结构化的节点级二元一致性检查,解决了长链推理中错误定位不准和注意力分散的难题。
- 通过将验证任务分解为轻量级的节点检查,该方法实现了精确的错误定位,并避免了昂贵的长文本生成与多重采样,显著增强了系统的可解释性与计算效率。
- 实验结果显示该方法在多个公共数据集上的 F1 分数相比基线提升了 10% 至 25%,同时 Token 消耗量比传统方法减少了 6 到 58 倍。



Shuo Yang, Zijian Yu, Zhenzhe Ying, Yuqin Dai, Guoqing Wang, Jun Lan, Jinfeng Xu, Jinze Li, Edith C.H. Ngai
- 提出了一个多模态融合框架,将视觉特征与语言模型有效结合,实现跨模态推理与生成能力的显著提升。
- 引入动态注意力机制,根据上下文自适应地调整视觉与文本信息的权重,从而提升了模型在多模态任务中的鲁棒性与泛化性。
- 在多项多模态基准测试(如图文匹配、视觉问答等)中,该方法均取得了优于现有方法的性能表现,验证了其有效性与先进性。

[AAAI26]Logic Unseen: Revealing the Logical Blindspots of Vision-Language Models
Yuchen Zhou, Jiayu Tang, Shuo Yang, Xiaoyan Xiao, Yuqin Dai, Wenhao Yang, Chao Gou, Xiaobo Xia, Tat-Seng Chua
- 提出 LogicBench 基准:构建了一个涵盖 9 类逻辑关系、4 种应用场景和 2 种评测任务的综合基准,包含超过 5 万对逻辑视觉-语言样本,用于系统性评估多模态大模型的逻辑理解能力。
- 开展系统性诊断评测:首次系统性分析多模态大模型在逻辑推理方面的表现,揭示了其在理解复杂逻辑结构时存在的显著“逻辑盲点”和固有限制。
- 提出 LogicCLIP 框架:设计了一种新型训练方法,有效增强模型的逻辑敏感性。实验表明,LogicCLIP 在多个领域显著提升逻辑理解能力的同时,还保持甚至超越了在标准视觉-语言基准上的表现。
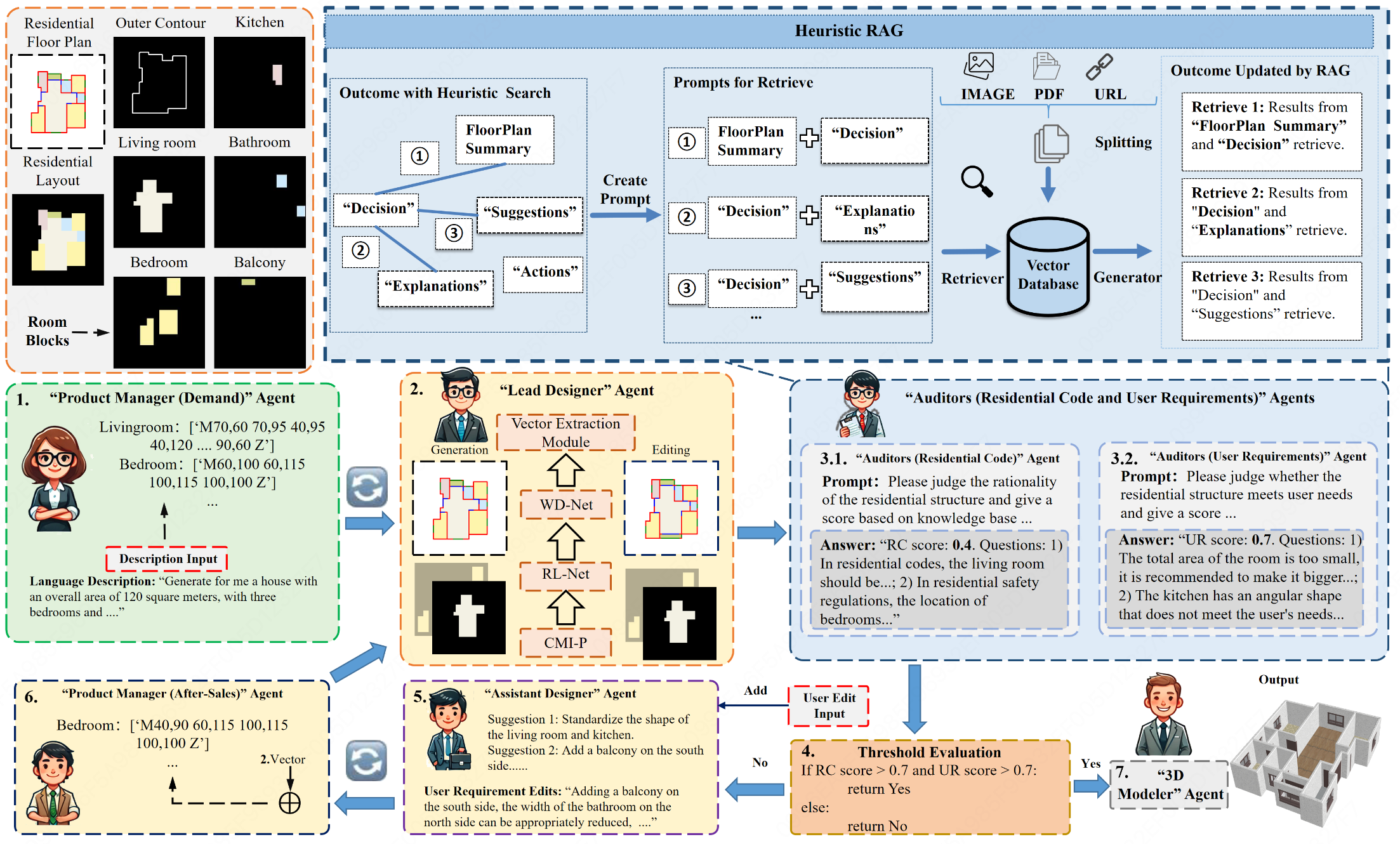
[EMNLP25]Card: Cross-modal agent framework for generative and editable residential design
Pengyu Zeng, Jun Yin, Miao Zhang, Yuqin Dai, Jizhizi Li, ZhanXiang Jin, Shuai Lu
- 提出 CARD 跨模态住宅设计框架,可从自然语言生成并编辑住宅布局。
- 设计 CMI-P 跨模态空间表示与 Text2FloorEdit 生成模型,实现标准化与可迭代设计。
- 构建包含规范审查、需求验证与 3D 可视化的多代理系统,支持普通用户无专业背景进行住宅设计。
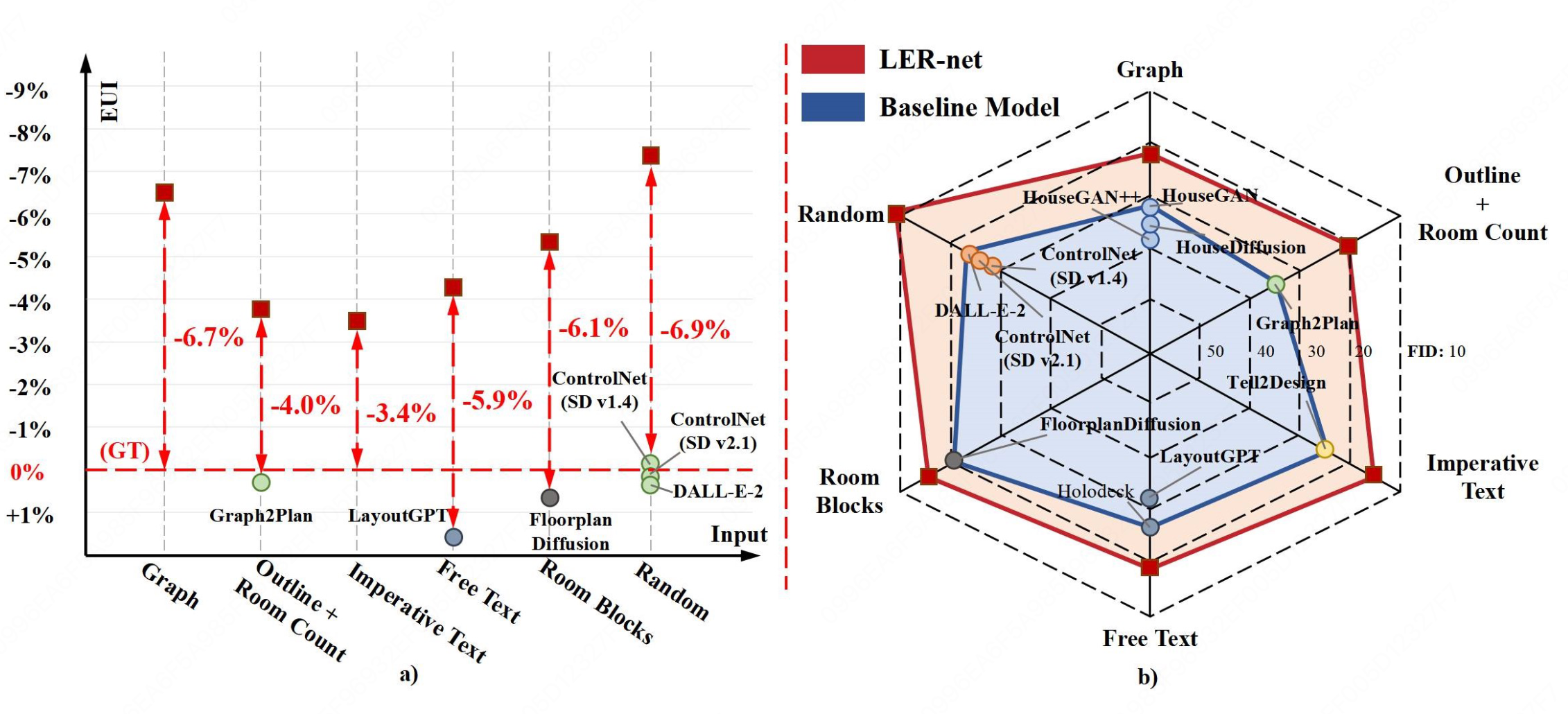
[ACM MM25]MRED-14: A Benchmark for Low-Energy Residential Floor Plan Generation with 14 Flexible Inputs
Pengyu Zeng, Jun Yin, Haoyuan Sun, Yuqin Dai, Maowei Jiang, Miao Zhang, Shuai Lu
- 构建首个包含14种输入类型的多模态住宅能耗数据集 MRED-14。
- 提出可灵活适配多输入的低能耗户型生成模型 LER-net。
- 实验验证模型能降低户型能耗并优于现有方法,具有实际设计可行性。
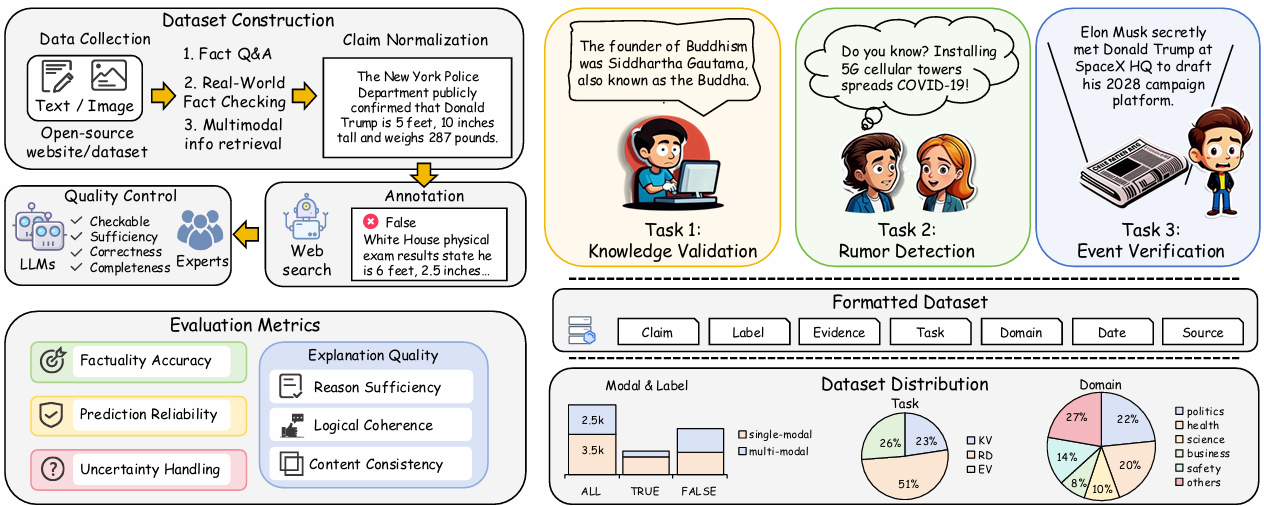
[ACMMM25 Datasets]RealFactBench: A Benchmark for Evaluating Large Language Models in Real-World Fact-Checking


Shuo Yang, Yuqin Dai, Guoqing Wang, Xinran Zheng, Jinfeng Xu, Jinze Li, Zhenzhe Ying, Weiqiang Wang, Edith CH Ngai.
- 我们提出 RealFactBench 基准测试集:构建了一个涵盖知识验证、谣言检测和事件核查等多种真实世界任务的综合性基准,用于评估大语言模型(LLMs)和多模态大模型(MLLMs)的事实核查能力。
- 引入新的评估指标 Unknown Rate (UnR):该指标用于更细致地衡量模型在不确定性处理方面的表现,帮助评估模型在保守性与自信程度之间的平衡。
- 开展大规模实证研究:在7个典型LLMs和4个MLLMs上进行了系统评估,揭示了当前模型在事实核查任务中的局限性,并为后续研究提供了有价值的洞察。
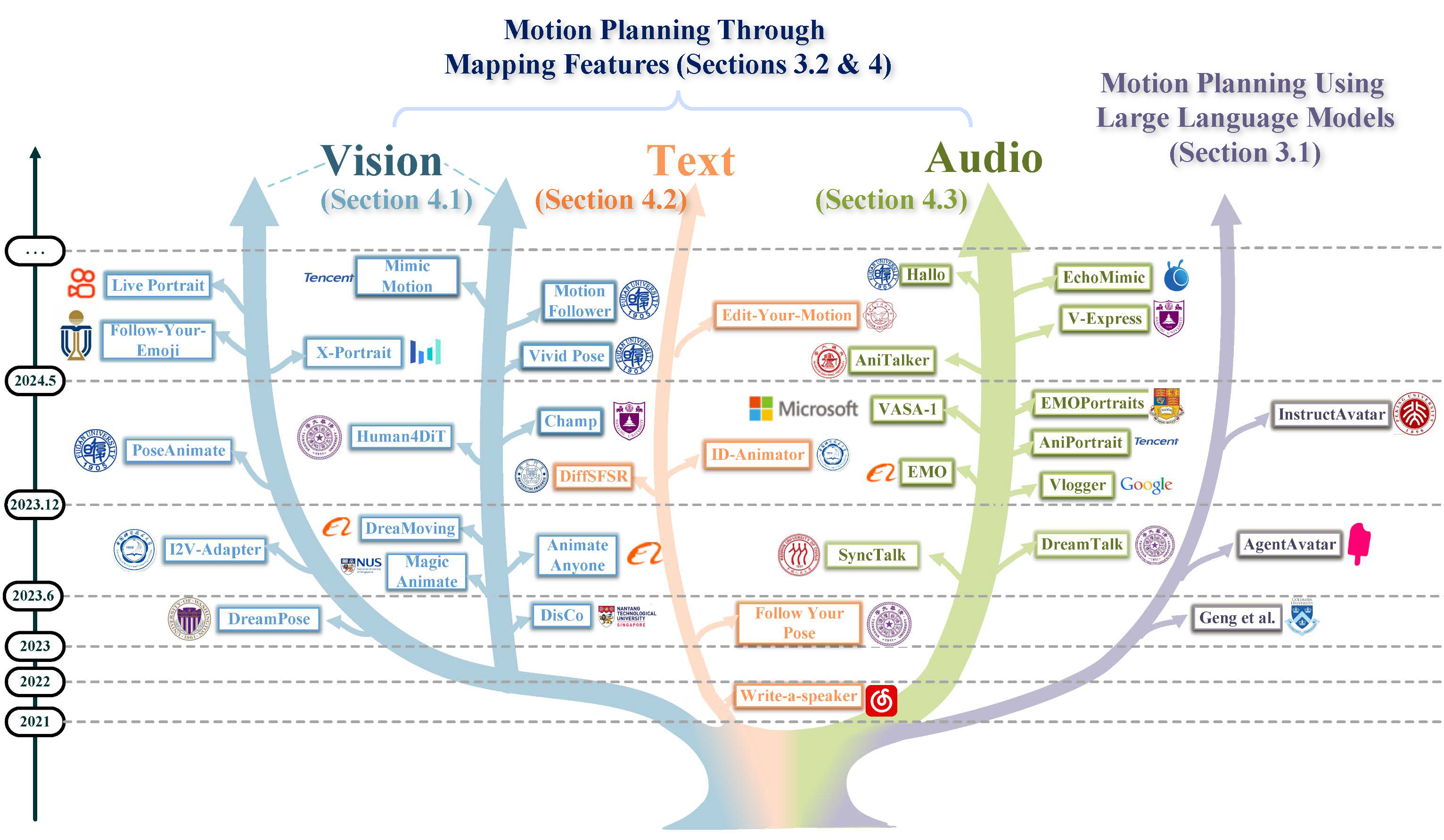
[TPAMI25]Human Motion Video Generation: A Survey


Haiwei Xue,Xiangyang Luo,Zhanghao Hu,Xin Zhang,Xunzhi Xiang,Yuqin Dai,Jianzhuang Liu,Zhensong Zhang,Minglei Li,Jian Yang,Fei Ma,Zhiyong Wu,Changpeng Yang,Zonghong Dai,Fei Richard Yu.
- 数字人视频生成领域综述.
- 总结了超过300篇最新数字人视频生成了领域相关文献的内容.
- 总结了现有数字人视频生成领域范式.
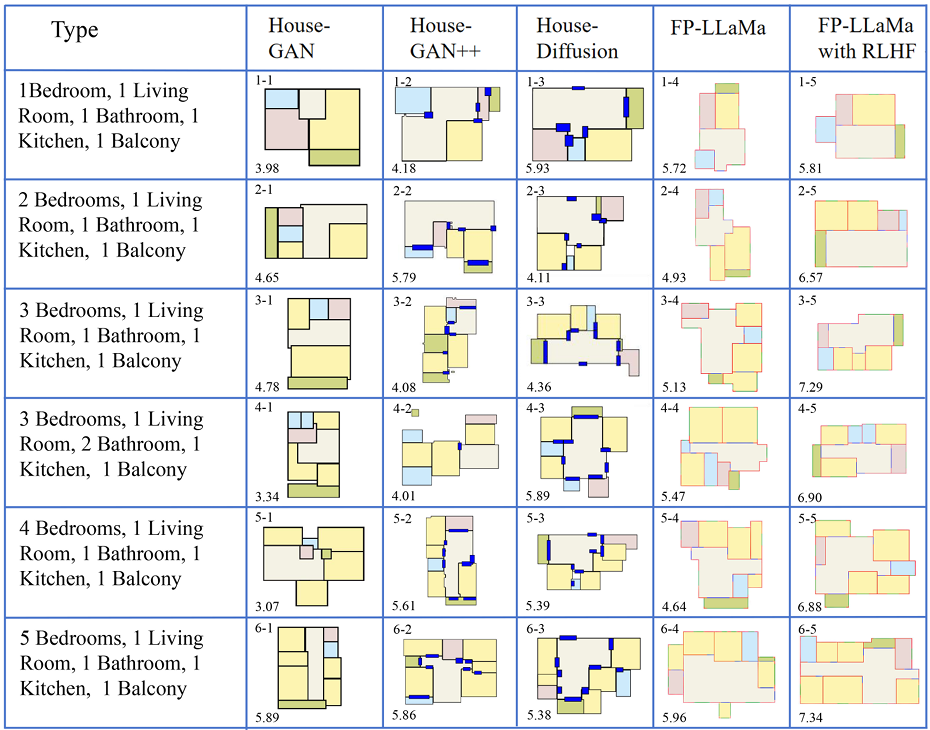
[ACL25 Oral]FloorPlan-LLaMa: Aligning Architects’ Feedback and Domain Knowledge in Architectural Floor Plan Generation


Jun Yin, Pengyu Zeng, Haoyuan Sun, Yuqin Dai, Han Zheng, Miao Zhang, Yachao Zhang, Shuai Lu
- 提出了ArchiMetricsNet数据集与FloorPlan-MPS评价模型:首次构建了一个包含功能性、流线性和整体性评估得分的楼面图数据集,并配有详细的文本分析,用以更贴近建筑专业知识地评估生成结果。
- 开发了FloorPlan-LLaMa生成模型并引入RLHF机制:设计了基于自回归框架的楼面图生成模型FloorPlan-LLaMa,并通过引入FloorPlan-MPS作为奖励模型,借助人类反馈强化学习(RLHF)机制使模型更符合建筑师的专业偏好。
- 实验证明方法优于现有基线并获专业认可:在文本条件和类别条件的生成任务中均优于现有基线模型,且经专业建筑师验证,其生成结果更为合理,契合人类设计偏好。
🎖 Honors and Awards
- 2022.10 华为智能基座奖学金
- 2020.10 国家留学基金委公派留学奖学金
🎓 Educations
- 2025.09 - 未来, 博士生, 清华大学
- 2022.06 - 至今, 硕士生, 南京理工大学
- 2020.01 - 2020.05, Visiting Student(Founded by IGSF, 国家留学基金委公派留学), University of Dayton
- 2018.09 - 2022.06, 本科, 南京理工大学
🏛️Professional Services
Student Reviewers:
- AAAI 2026
- ICLR 2026
🏋️ Skills
英语能力
-
IELTS 7.0
in 2019, 2020.
-
CET6 575
in 2020.
-
CET4 623
in 2019.
社交技能
🏓一点业余乒乓球>🎤卡拉永远ok>👥TRPG»🏸喜欢(站桩输出的)双打羽毛球